This morning, after 8 months, I finally finished reading High Performance MySQL: Optimization, Backups, Replication, and More by Baron Schwartz, Peter Zaitsev, and Vadim Tkachenko - otherwise known as the brains behind Percona. And by "finished", what I mean is that I read about 400 pages and then spot-read the remaining 426 pages. That's right - it's over 800 pages; this book is a freakin' beast! It's like reading an Encyclopedia Britannica; only, one in which every volume covers MySQL. It's long, and tedious, and mind numbing. And, I kind of loved it!
 | ||||
I'm tempted to tell you that this is not a book for the casual SQL developer. But, I think there's a great amount of value here for everyone. At the end of the day, I'm really just a "SQL enthusiast" - I don't know thing-one about administering a MySQL relational database management system (MySQL, Percona, AWS RDS, or otherwise). But, I have to admit it was fascinating to see how the entire stack comes together. From query preparation and binary protocols, to the SQL parser and optimizer, to the various storage engines, to battery-backed RAID (Redundant Array of Inexpensive Drives) caches for the binlog, to index structuring, record storage, and data-type representation at the bit-level.
Mental Note: Never ever use MyISAM. Even when you think you have a use-case for it, don't use it. Never. Not ever. (Kindle Locations 895-897)
If you're just a SQL enthusiast, like myself, I'd recon that the first half of the book is the most valuable when it comes to shaping the way you think about data-table design, index structure, and query performance. Plus, it's not a novel - the sections are clearly delineated and don't necessarily build on top of each other. For example, I spot-read (er, um, skipped) the chapter on Operating System and Hardware Optimization; but, I thoroughly read a subsequent chapter on Application-Level Optimization.
Speaking of SQL enthusiasm, one of my passions is to go into our application and try to optimize specific sets of queries. Brad Brewer, our database administrator, strongly encourages me not to do this. He argues that it ends up hiding application-level problems. Apparently, so do the Percona engineers:
Getting rid of filesorts and temporary tables is a catch-all, "best practice" type of tactic. Generic "best practices" reviews have their place, but they are seldom the solution to highly specific problems. The problem could easily have been misconfiguration, for example. We've seen many cases where someone tried to fix a misconfigured server with tactics such as optimizing queries, which was ultimately a waste of time and just prolonged the damage caused by the real problem. (Kindle Locations 2961-2964)
Well played, Brad, well played.
Some of what I read in the book - like the previous statements - went against preconceived notions that I held about SQL. Other things that I read happend to agree with me. For example, I'm not shy about my general dislike of the NULL column in a database. And, for what it's worth, at least in some ways, the Percona engineers share some of that frustration:
Avoid NULL if possible... A lot of tables include nullable columns even when the application does not need to store NULL (the absence of a value), merely because it's the default. It's usually best to specify columns as NOT NULL unless you intend to store NULL in them.
It's harder for MySQL to optimize queries that refer to nullable columns, because they make indexes, index statistics, and value comparisons more complicated. A nullable column uses more storage space and requires special processing inside MySQL. When a nullable column is indexed, it requires an extra byte per entry and can even cause a fixed-size index (such as an index on a single integer column) to be converted to a variable-sized one in MyISAM.
The performance improvement from changing NULL columns to NOT NULL is usually small, so don't make it a priority to find and change them on an existing schema unless you know they are causing problems. However, if you're planning to index columns, avoid making them nullable if possible.
.... we suggest considering alternatives when possible. Even when you do need to store a "no value" fact in a table, you might not need to use NULL. Perhaps you can use zero, a special value, or an empty string instead. (Kindle Locations 3133-3142, 3588-3590)
It's harder for MySQL to optimize queries that refer to nullable columns, because they make indexes, index statistics, and value comparisons more complicated. A nullable column uses more storage space and requires special processing inside MySQL. When a nullable column is indexed, it requires an extra byte per entry and can even cause a fixed-size index (such as an index on a single integer column) to be converted to a variable-sized one in MyISAM.
The performance improvement from changing NULL columns to NOT NULL is usually small, so don't make it a priority to find and change them on an existing schema unless you know they are causing problems. However, if you're planning to index columns, avoid making them nullable if possible.
.... we suggest considering alternatives when possible. Even when you do need to store a "no value" fact in a table, you might not need to use NULL. Perhaps you can use zero, a special value, or an empty string instead. (Kindle Locations 3133-3142, 3588-3590)
And, of course, my dislike of Foreign Keys:
Instead of using foreign keys as constraints, it's often a good idea to constrain the values in the application. Foreign keys can add significant overhead. We don't have any benchmarks to share, but we have seen many cases where server profiling revealed that foreign key constraint checks were the performance problem, and removing the foreign keys improved performance greatly. (Kindle Locations 7377-7380)
But, the pats-on-the-back were few and far between. Most of what I read in the book was either completely new; or, covered things in a level of detail far beyond my understanding. One of the coolest and most intriguing topics that the book discussed was the inclusion of "low selectivity" columns in an index. And, not just that, including them as an index prefix.
Here's the trick: even if a query that doesn't restrict the results by sex is issued, we can ensure that the index is usable anyway by adding AND sex IN('m', 'f') to the WHERE clause. This won't actually filter out any rows, so it's functionally the same as not including the sex column in the WHERE clause at all. However, we need to include this column, because it'll let MySQL use a larger prefix of the index. This trick is useful in situations like this one, but if the column had many distinct values, it wouldn't work well because the IN() list would get too large. (Kindle Locations 4997-5002)
This kind of thinking really blew my mind. Even right now, I can think of placed within InVision that could leverage these simple index prefixes - columns like "isArchive" and "isSample". Of course, using these IN()-based index columns does make the SQL more complex and requires the rest of your team to understand how it works. So, it's not necessarily a clear win.
Another fascinating topic was the concept of "deferred joins" in which an inner-query uses a covering index in order to find the primary-keys used to power the outer query:
We call this a "deferred join" because it defers access to the columns. MySQL uses the covering index in the first stage of the query, when it finds matching rows in the subquery in the FROM clause. It doesn't use the index to cover the whole query, but it's better than nothing. (Kindle Locations 4711-4713)
The performance of a deferred join depends on the type and distribution of data in the database.
After reading about "deferred joins", I realize that I actually have used this approach in the past, when grabbing a subset of IDs. Sometimes, I need to work with a "recent" subset of data; but, I need to filter and order the results in a way that can't leverage an existing index. In such cases, I'll use a deferred join to gather just the IDs in a derived table; then, join that derived table back to the same table to do the slower work:
But, this brings up the a titillating topic of conversation: joins. Back when I was younger and really excited about learning SQL, I started creating huge, monstrous, massive JOIN statements. Four, 5, 6 tables in a series of JOINS - I didn't care - the more the merrier. But, as I've gotten older and more mature (I should hope), my thinking about JOINs has continued to evolve
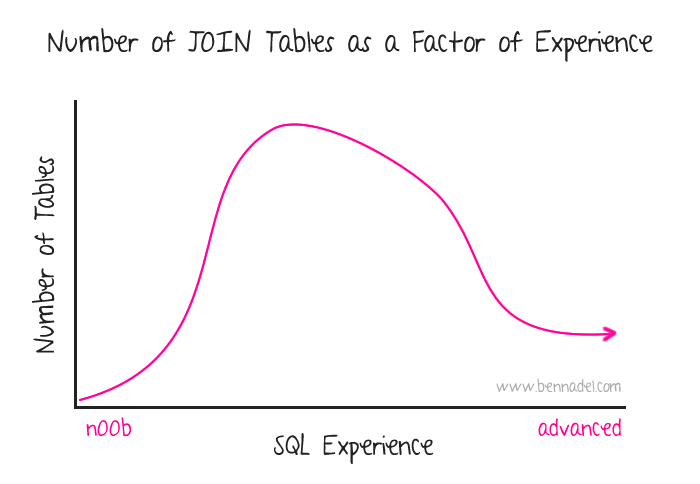 | ||||
This thinking happens to align with much of what I was reading in the book:
The traditional approach to database design emphasizes doing as much work as possible with as few queries as possible. This approach was historically better because of the cost of network communication and the overhead of the query parsing and optimization stages.
However, this advice doesn't apply as much to MySQL, because it was designed to handle connecting and disconnecting very efficiently and to respond to small and simple queries very quickly. Modern networks are also significantly faster than they used to be, reducing network latency. Depending on the server version, MySQL can run well over 100,000 simple queries per second on commodity server hardware and over 2,000 queries per second from a single correspondent on a gigabit network, so running multiple queries isn't necessarily such a bad thing.
Connection response is still slow compared to the number of rows MySQL can traverse per second internally, though, which is counted in millions per second for in-memory data. All else being equal, it's still a good idea to use as few queries as possible, but sometimes you can make a query more efficient by decomposing it and executing a few simple queries instead of one complex one.
.... Many high-performance applications use join decomposition. You can decompose a join by running multiple single-table queries instead of a multitable join, and then performing the join in the application....
Why on earth would you do this? It looks wasteful at first glance, because you've increased the number of queries without getting anything in return. However, such restructuring can actually give significant performance advantages:
* Caching can be more efficient. Many applications cache "objects" that map directly to tables. In this example, if the object with the tag mysql is already cached, the application can skip the first query. If you find posts with an ID of 123, 567, or 9098 in the cache, you can remove them from the IN() list. The query cache might also benefit from this strategy. If only one of the tables changes frequently, decomposing a join can reduce the number of cache invalidations.
* Executing the queries individually can sometimes reduce lock contention.
* Doing joins in the application makes it easier to scale the database by placing tables on different servers.
* The queries themselves can be more efficient. In this example, using an IN() list instead of a join lets MySQL sort row IDs and retrieve rows more optimally than might be possible with a join. We explain this in more detail later.
* You can reduce redundant row accesses. (Kindle Locations 5471-5480, 5500-5519)
However, this advice doesn't apply as much to MySQL, because it was designed to handle connecting and disconnecting very efficiently and to respond to small and simple queries very quickly. Modern networks are also significantly faster than they used to be, reducing network latency. Depending on the server version, MySQL can run well over 100,000 simple queries per second on commodity server hardware and over 2,000 queries per second from a single correspondent on a gigabit network, so running multiple queries isn't necessarily such a bad thing.
Connection response is still slow compared to the number of rows MySQL can traverse per second internally, though, which is counted in millions per second for in-memory data. All else being equal, it's still a good idea to use as few queries as possible, but sometimes you can make a query more efficient by decomposing it and executing a few simple queries instead of one complex one.
.... Many high-performance applications use join decomposition. You can decompose a join by running multiple single-table queries instead of a multitable join, and then performing the join in the application....
Why on earth would you do this? It looks wasteful at first glance, because you've increased the number of queries without getting anything in return. However, such restructuring can actually give significant performance advantages:
* Caching can be more efficient. Many applications cache "objects" that map directly to tables. In this example, if the object with the tag mysql is already cached, the application can skip the first query. If you find posts with an ID of 123, 567, or 9098 in the cache, you can remove them from the IN() list. The query cache might also benefit from this strategy. If only one of the tables changes frequently, decomposing a join can reduce the number of cache invalidations.
* Executing the queries individually can sometimes reduce lock contention.
* Doing joins in the application makes it easier to scale the database by placing tables on different servers.
* The queries themselves can be more efficient. In this example, using an IN() list instead of a join lets MySQL sort row IDs and retrieve rows more optimally than might be possible with a join. We explain this in more detail later.
* You can reduce redundant row accesses. (Kindle Locations 5471-5480, 5500-5519)
Awesome stuff, right? And honestly, I could just keep going on and on (did I mention the book is 826 pages long?). But, I'll just end with two more interesting passages that I had starred and bookmarked:
MySQL applies algebraic transformations to simplify and canonicalize expressions. It can also fold and reduce constants, eliminating impossible constraints and constant conditions. For example, the term (5 = 5 AND a > 5) will reduce to just a > 5. Similarly, (a < b AND b = c) AND a = 5 becomes b > 5 AND b = c AND a = 5. (Kindle Locations 5682-5683)
How many of you start a dynamically generated WHERE clause with "1 = 1" so that all your subsequent conditions can start with "AND"? I know I do, all the time. And, it turns out, the query parser just removes it when normalizing the query structure. Outstanding!
And this one about IN():
IN() list comparisons... In many database servers, IN() is just a synonym for multiple OR clauses, because the two are logically equivalent. Not so in MySQL, which sorts the values in the IN() list and uses a fast binary search to see whether a value is in the list. This is O( log n) in the size of the list, whereas an equivalent series of OR clauses is O( n) in the size of the list (i.e., much slower for large lists). (Kindle Locations 5757-5762)
High Performance MySQL is not an easy book to get through, especially if you're not administrering an RDMS. I really only read about half of it. But, the half that I did read was very thought-provoking and has changed the way that I think about SQL. If you're interesting in really digging deep into SQL, it's definitely a book that I would recommend (even if only for the first-half).








0 comments:
Post a Comment