Awk command in Unix / Linux is a powerful command for processing text. Administrator & developer often need to look for the pattern in the files and then process that text as per there requirement. Awk command comes quite handy for these types of task. It is very helpful for processing table i.e (rows and column) type of data in the files. awk is quite powerful scripting tools and we can also do arithmetic operations on it. In a nutshell,this is something every body working on Linux should be aware . In this post,i will explain little about awk syntax , records,fields ,line Separator and the provide 21 awk command in Linux with examples which is quite useful and it will helpful you understand the overall picture of the awk command. Here are the topics for Unix awk command
What is awk command in Linux?
a)awk command is a powerful Pattern Scanning and Processing Language.
b)it is a programming language whose basic operation is to search a set of files for
patterns, and to perform specified actions upon lines or fields of lines which contain
instances of those patterns. It also count the occurrence of the pattern
patterns, and to perform specified actions upon lines or fields of lines which contain
instances of those patterns. It also count the occurrence of the pattern
An awk program is a sequence of statements of the form:
pattern { action }
pattern { action }
…Usage: awk -f pfile [files]
pattern { action }
…Usage: awk -f pfile [files]
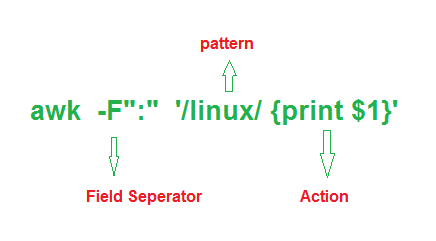
How awk command in Linux works
a) Awk input is divided into “records” terminated by a record separator. The default record separator is a newline, so by default awk processes its input a line at a time. The number of the current record is available in a variable named NR.
b)Each input record is considered to be divided into “fields.” Fields are normally separated by white space — blanks or tabs. Fields are referred to as $1, $2, and so forth, where $1 is the first field, and $0 is the whole input record itself. Fields may be assigned to e.g., to swap $5 and $6 awk “{temp=$5; $5=$6; $6=temp; print $0}” filename. The number of fields in the current record is available in a variable named NF.
We can put all the pattern action in the file and execute against a set of file
We can put all the pattern action in the file and execute against a set of file
Usage: awk ‘program’ [filename]*
Example
awk -f cmdfile [filename]*
Example
awk -f cmdfile [filename]*
What is awk patterns
Selector that determines whether action is to be executed
pattern can be:
a)the special token BEGIN or END
b) regular expressions
c) arithmetic relation operators
d) string-valued expressions
e) arbitrary combination of the above
a)the special token BEGIN or END
b) regular expressions
c) arithmetic relation operators
d) string-valued expressions
e) arbitrary combination of the above
BEGIN and END provide a way to gain control before and after processing, for initialization and wrap-up.
BEGIN: actions are performed before the first input line is read.It is called preprocessing
END: actions are done after the last input line has been processed.It is post processing
BEGIN: actions are performed before the first input line is read.It is called preprocessing
END: actions are done after the last input line has been processed.It is post processing
What is awk fields:
a)Each input line is split into fields.
b)FS: field separator: default is blanks or tabs
c) $0 is the entire line
d)$1 is the first field, $2 is the second field, …. $NF
e) NF is a built-in variable whose value is set to the number of fields.
b)FS: field separator: default is blanks or tabs
c) $0 is the entire line
d)$1 is the first field, $2 is the second field, …. $NF
e) NF is a built-in variable whose value is set to the number of fields.
What is awk records:
a)newline: Default record separator
b)So, by default, AWK processes its input a line at a time.
c)NR is the variable whose value is the number of the current record.
d) RS: record separator
b)So, by default, AWK processes its input a line at a time.
c)NR is the variable whose value is the number of the current record.
d) RS: record separator
What is Awk command Working Methodology
a)Awk reads the input files one line at a time.Each line is called record and Each record is splits into the field
b) For each line, it matches with given pattern in the given order, if matches performs the corresponding action.
b) For each line, it matches with given pattern in the given order, if matches performs the corresponding action.
| cat file1|awk ‘pattern { action }’ |
c) If no pattern matches, no action will be performed.
d.In the above syntax, either search pattern or action are optional, But not both.
e)If the search pattern is not given, then Awk performs the given actions for each line of the input.
d.In the above syntax, either search pattern or action are optional, But not both.
e)If the search pattern is not given, then Awk performs the given actions for each line of the input.
| cat file1|awk ‘ { action }’ |
f)If the action is not given, print all that lines that matches with the given patterns which is the default action.
e)Empty braces with out any action does nothing. It wont perform default printing operation.
e)Empty braces with out any action does nothing. It wont perform default printing operation.
Some important function in unix
Functions:
length function to compute length of a string e.g. { print length, $0}
substr(s, m, n) produces the sub-string of s that begins at position m and is at most n characters long.
Functions:
length function to compute length of a string e.g. { print length, $0}
substr(s, m, n) produces the sub-string of s that begins at position m and is at most n characters long.
21 awk command examples in Linux
Here are some good awk examples or awk command in Linux with examples
1) suppose we want to know names of oracle database running on the server, then below command can be used
$ ps -ef|grep pmon|grep -v grep|awk ‘{print $NF}’|awk -F”_” ‘{print $NF}’
DEV
DEV
SAT
awk print $NF -print the last column

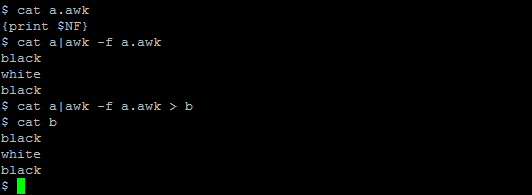
2) More complex awk scripts need to be run from a file. The syntax for such cases is:
cat input1 | awk -f a.awk > output1where input1 is the input file, output1 is the output file, and a.awk is a file containing awk commands.
3) awk Variables
NR – Line number of current input line.
NR – Line number of current input line.
NF – Number of fields in the current line.
The variable FILENAME contains the name of the current input file.
OFS – Output Field seperator
FS: Field seperator
RS: Record seperator
{ print NR, NF, $0 } – if items are not separated by commas the output will be concatenated.
$ cat test.lst
grant CREATE TYPE
grant CREATE SYNONYM
$ awk ‘{print $1,$NF,$0 }’ test.lst
grant TYPE grant CREATE TYPE
grant SYNONYM grant CREATE SYNONYM

4) To print the length of the column
awk ‘{print length($2)}’ file – Print length of string in 2nd column
$ awk ‘{print length($2)}’ test.lst
6
6
5) Add up first second, print sum and average using END
This command in useful in calculating the filesystem size
awk ‘ { s += $2 } END { print “sum is”, s, ” average is”, s/NR }’
This command in useful in calculating the filesystem size
awk ‘ { s += $2 } END { print “sum is”, s, ” average is”, s/NR }’
/dev/1v00 52428800 12008924 78% 145564 6% /u1100
/dev/2lv01 314572800 54338800 83% 4242 1% /u1101
/dev/2lv01 314572800 54338800 83% 4242 1% /u1101
/dev/3v02 104857600 95071164 10% 12000 1% /u1102
/dev/4v02 51380224 44676480 14% 38310 1% /u1103
/dev/5vo2 784334848 89600124 89% 139 1% /u1104
$ df -k|awk ‘{ s += $2 } END { print “sum is”, s, ” average is”, s/NR }’
sum is 1338377216 average is 8.92251e+07
$ df -k|awk ‘{ s += $2 } END { print “sum is”, s, ” average is”, s/NR }’
sum is 1307574272 average is 2.61515e+08
$ df -k|awk ‘{ s += $2 } END { print “sum is”, s, ” average is”, s/NR/1024 }’
sum is 1307574272 average is 255386
6) How to print the last line with awk command
awk ‘{line = $0} END {print line}‘ – Print the last line

7) Print the total number of lines that contain the word scott
cat test2.txt|awk ‘/scott/ {tlines = tlines + 1} END {print tlines}‘

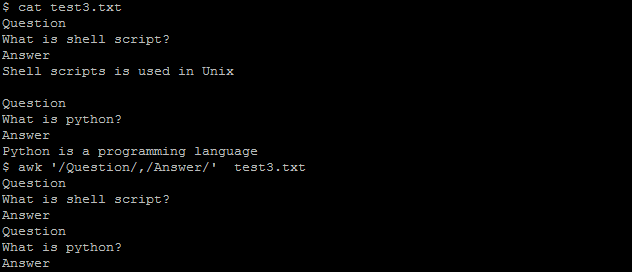
8) Print Lines Between Two Patterns with AWK
awk ‘/start/, /stop/’ file
9) Print all lines whose first field is different from previous one
awk ‘$1 != prev { print; prev = $1 }’ file

10) Print column 3 if column 2 > column 1
awk ‘$2 > $1 {print $3}’ file
11) Count number of lines where col 3 > col 1
awk ‘$3 > $1 {print i + “1”; i++}’ file
Print every line after erasing the 2nd field
awk ‘{$2 = “”; print}’ file
12 ) awk field separator : If you have another character that delimits fields, use the -F option.
If the delimiter is |
If the delimiter is |
awk -F”|” ‘$2==”High”{print $4}’ filename
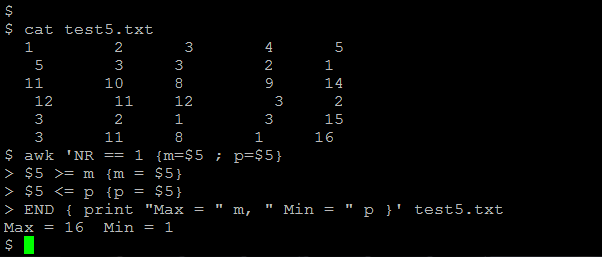
13) The below action can be used to Find maximum and minimum values present in column 5
NR == 1 {m=$5 ; p=$5}
$5 >= m {m = $5}
$5 <= p {p = $5}
END { print “Max = ” m, ” Min = ” p }
$5 >= m {m = $5}
$5 <= p {p = $5}
END { print “Max = ” m, ” Min = ” p }
14) Example of defining variables, multiple commands on one line
NR == 1 {prev=$4; preva = $1; prevb = $2; n=0; sum=0}
$4 != prev {print preva, prevb, prev, sum/n; n=0; sum=0; prev = $4; preva = $1; prevb = $2}
$4 == prev {n++; sum=sum+$5/$6}
END {print preva, prevb, prev, sum/n}
$4 != prev {print preva, prevb, prev, sum/n; n=0; sum=0; prev = $4; preva = $1; prevb = $2}
$4 == prev {n++; sum=sum+$5/$6}
END {print preva, prevb, prev, sum/n}
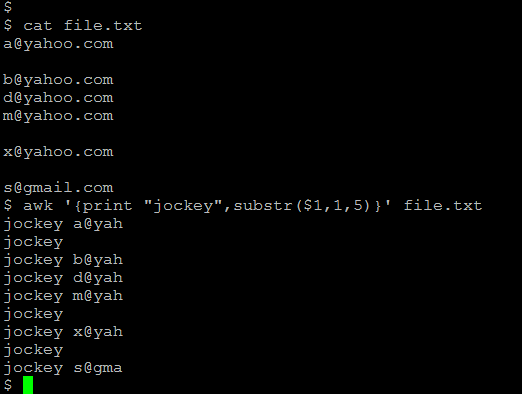
15) Example of using substrings:
substr($1,1,5) picks out characters 1 thru 5 of column 1
awk ‘{print “jockey”,substr($1,1,5)}’ file.txt
16) Print command emulates the cat command of Unix
{ print $1 >”foo1″; print $2 >>”foo2″ } – Output may be diverted to multiple files. There is a limit
on the number of output files; currently it is 10.
on the number of output files; currently it is 10.
The file name can be a variable or a field as well as a constant; for example,
print $1 >$2
uses the contents of field 2 as a file name.
print $1 >$2
uses the contents of field 2 as a file name.
17) length > 72 – prints all input lines whose length exceeds 72 characters.
awk ‘ length($1) > 5 {print $5}’
18)Print first two fields in opposite order
cat file|awk { print $2, $1 }
19) print all lines which do not have word Format.
$0 !~ /Format/
20) Just tell Awk to print an extra blank line if the current line is not blank:
awk ‘{print ; if (NF != 0) print “”}’ infile > outfile
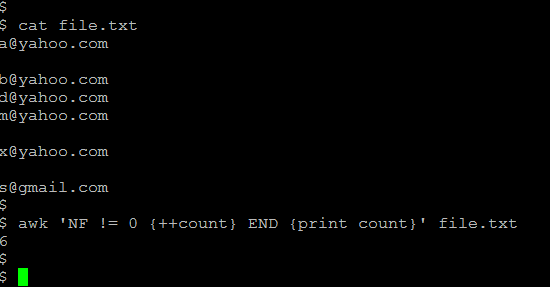
21) Count the non-empty lines.The email addresses of various different groups were placed on consecutive lines in the file, with the different groups separated by blank lines. If I wanted to quickly and reliably determine how many people were on the distribution list, then use:
awk ‘NF != 0 {++count} END {print count}’ list
 \
\
Frequently asked question on awk command
1) What is the abbreviation of awk in Unix/Linux?
Answer
Answer
Awk stands for the names of its authors “Aho, Weinberger, and Kernighan”. it is a powerful programming language which allows easy manipulation of structured data and the generation of formatted reports.it is mostly used for pattern scanning and processing.
2) What is awk/nawk and gawk?
Answer
Awk : AWK is original AWK written by A. Aho, B. W. Kernighan and P. Weinberger.
Nawk: NAWK stands for “New AWK”. This is AT&T’s version of the Awk.
Gawk : GAWK stands for “GNU AWK”. All Linux distributions comes with GAWK. This is fully compatible with AWK and NAWK.
nawk and gawk has additional features than awk
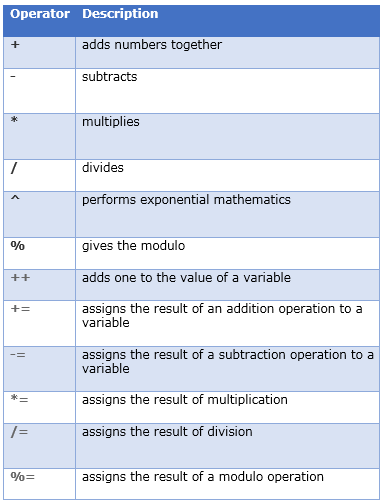
3) What maths operation awk provides?
Answer
More awk Linux command examples
- print the total size of files in the directory
ls -l . | awk ‘{ i += $5 } ; END { print “total bytes: ” i }’
2) print the max length of column
awk ‘{ if (length($4) > max) max = length($4) } END { print max }’
3. Arithmetic Function are also allowed
awk ‘{ print “square root of”, $1, “is”, sqrt($1) }’
Conclusion
awk is a powerful pattern search and processing command in Linux/Unix. Complicated search task can be done easily using it.Hope you like this article on awk command in Linux with examples








0 comments:
Post a Comment