In this article I’ll explain how MySQL’s index structures enable an extremely important query optimization, and how that differs between storage engines. I’ll also show you how to know and predict when the optimization is triggered, how to design tables and queries so it’ll be used, and how to avoid defeating it with poor practices. Plus, I’ll peek a bit into InnoDB internals to show you what’s going on behind the scenes.
A review of MySQL’s primary and secondary indexes
You need to understand how MySQL’s indexes work, and how InnoDB’s are different from other storage engines, such as MyISAM, because if you don’t, you can’t design tables effectively.
The InnoDB storage engine creates a clustered index for every table. If the table has a primary key, that is the clustered index. If not, InnoDB internally assigns a six-byte unique ID to every row and uses that as the clustered index. (Moral of the story: pick a primary key of your own—don’t let it generate a useless one for you).
All indexes are B-trees. In InnoDB, the primary key’s leaf nodes are the data. Secondary indexes have a pointer to the data at their leaf nodes. A picture is worth a thousand words, so here’s a diagram of the table structure I’ll use later on in this article.
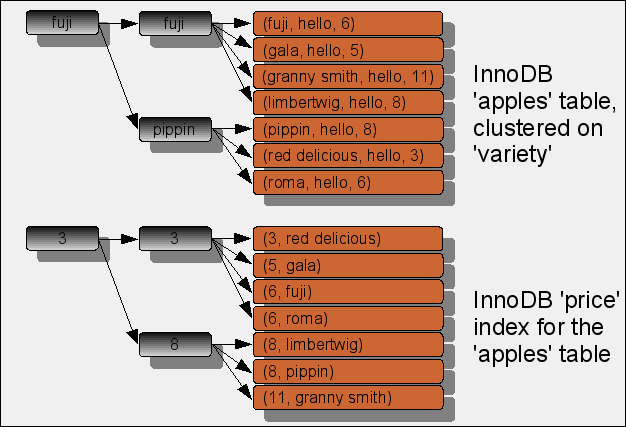
MyISAM has no clustered index, so the data isn’t physically ordered by any index (it’s in insertion order), but in InnoDB, the rows are physically ordered by the primary key. That means there can be page splits as rows are inserted between other rows—if there are too many rows to fit on a page, the page has to be split. MyISAM doesn’t have that problem, because rows don’t get stuffed between other rows (they are added at the end), so a secondary index’s leaf nodes always point directly to the row in the table. In fact, there’s no functional difference between primary and secondary keys in MyISAM. A MyISAM primary key is simply a unique index named “PRIMARY.”
Here’s a picture of the equivalent table structure, using the MyISAM engine. Notice how different it is from InnoDB! This is the same table, it’s just a different storage engine.
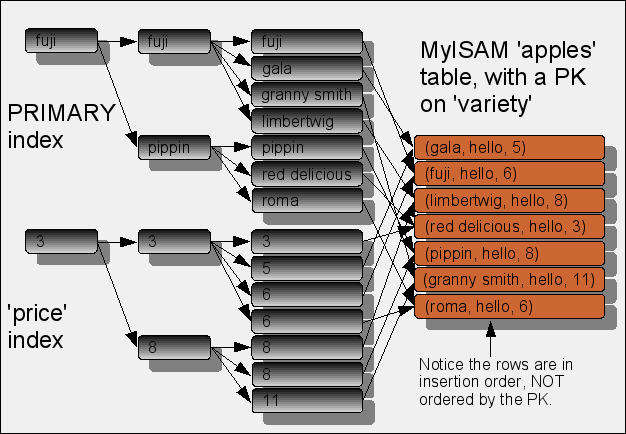
Why doesn’t InnoDB just “point” to the rows like MyISAM? If InnoDB used that strategy, it would have to rewrite all the secondary indexes at every page split, when the rows get moved to a different location on disk. To avoid that cost, InnoDB uses the values from the primary key as its secondary index’s leaf nodes. That makes the secondary indexes independent of the physical order of the primary key, but the “pointer” isn’t a pointer directly to the row as in MyISAM. It also means secondary index lookups are more expensive than primary key lookups, because any secondary index lookup only results in a tuple that can be used to navigate the primary key—double work. MyISAM doesn’t have that issue. Of course, it doesn’t have rows in index order, either; and the primary key might be “deeper.” It’s a trade-off.
Secondary index optimizations
So there’s a cost to secondary indexes in InnoDB. There’s an optimization too. Once a query navigates to the leaf node of a secondary index, it knows two things: the values it used to navigate the index, and the primary key values of that row in the table.
For example, suppose I have a table structured like this:
create table apples(
variety varchar(10) primary key,
note varchar(50),
price int,
key(price)
) engine=InnoDB;
insert into apples values
('gala', 'hello', 5),
('fuji', 'hello', 6),
('limbertwig', 'hello', 8),
('red delicious', 'hello', 3),
('pippin', 'hello', 8),
('granny smith', 'hello', 11),
('roma', 'hello', 6);
Note only the ‘gala’ row has a
price of 5. Now suppose I issue the following query:select variety from apples where price=5;
The query takes the value 5 and navigates the
price index. When it gets to the leaf node, it finds the value ‘gala’, which it can use to navigate the primary key. But why does it need to do that? It already has the value it was looking for!
In fact, if the query only refers to values in the secondary and clustered index, it doesn’t need to leave the secondary index. If you like fancy lingo, the index “covers” the query, so it is a “covering index” or “index cover.”
This is a fantastic optimization. It means each secondary index is like another table, clustered index-first. In this example, the secondary index is like a table containing just
price and variety, clustered in that order (refer again to the diagrams above).
In MyISAM, the “don’t leave the index” optimization can be used too, but only if the query refers only to values in the index itself, because MyISAM indexes don’t have any PK values at their leaf nodes. A MyISAM index can’t be used to find any additional data without following the pointer to the row itself. Again, it’s a trade-off.
How to know when the optimization is used
Theoretically, the optimization can be used anytime a query only uses values from the clustered index and a secondary index in InnoDB, or only uses values from the index itself in MyISAM. That doesn’t mean the query will use that index, though. For a variety of reasons, the query might use some other index. To find out for sure, EXPLAIN the query. If the
Extra column includes the text “Using index,” the optimization is being used.How to design indexes for this optimization
Once you understand how indexes work, you can make deliberate decisions about indexes. Here is a methodical approach to designing indexes.
Begin with a table and the data it needs, but without any indexes except those designed to constrain the data to valid values (primary and unique indexes). Next, consider the queries that are issued against the table. Is it queried ad-hoc, or do certain types of queries happen repeatedly? This is very important to know.
Before you start, consider the size of the table and how much it is used. You should put your optimization effort where it is most needed. If one 5-minute query runs once a day and you know it should be possible to optimize it to 5 seconds, that’s 4 minutes and 55 seconds saved. If another query issued every minute takes 5 seconds and you know it should be possible to run it in a few milliseconds, that’s about 7,000 seconds saved. You should optimize the second query first. You should also consider carefully-designed archiving jobs to get those tables as small as possible. Smaller tables are a huge optimization.
Now, back to the index design discussion. If the table is queried ad-hoc all the time, you need to create generally useful indexes. Most of the time you should examine the data to figure out what they should be. Pretend you’re optimizing the
apples table above. This table probably does not need an index on the note column. Look at its contents—every row just says “hello.” Indexing that would be a total waste. Plus, it just seems reasonable that you want to look at the note, but not filter by it. On the other hand, it’s very reasonable that you’d want to find apples by price. The price index is probably a good choice.
On the other hand, if you know there’s a certain query that happens all the time and needs to be very fast, you should consider specially optimized indexes. Suppose these two queries each run 50 times a second:
select variety from apples where price = ?;
select note from apples where price = ?;
These queries deserve a close look. The optimization strategy will depend on the table size and the storage engine.
If you are using the InnoDB engine, the first query is already optimized as we’ve seen above. It will use the
price index and not even look at the table itself. If you’re using the MyISAM engine, you need to consider how large the table is, and therefore how large an index on (price, variety) would be. If the table is very large, for example, if there are a bunch of large VARCHAR columns in it, that index might be significantly faster than all the bookmark lookups required to find the variety column for each row found in an index that only contains the price column.
The second query is trickier to optimize, because it really depends on how large the table is. If the table is very large, and has lots of other columns as I mentioned in the previous paragraph, it might make sense to create an index on
(price, note). This is where careful testing is needed. I will explain how to do that testing in an upcoming article. It is non-trivial in MySQL, unfortunately.
The general strategy is as follows:
- For InnoDB, put the columns in the
WHEREclause first in the index, then add the columns named in theSELECTclause at the end, unless they are included in the primary key. - For MyISAM, put the columns in the
WHEREclause first in the index, then add the columns named in theSELECTclause at the end.
How to write queries that don’t suck
I’ve noticed many people have a tendency to write
SELECT * FROM... queries. If you don’t need all the columns, don’t select all the columns, because it can make the difference between a fast and a slow query. If you only select the columns you need, your query might be able to use one of the optimizations I’ve just explained. If you select every column and the query uses a secondary index, there’s no way to do that, and the query will have to wander around indexes finding the rows it needs, then do other operations to get the actual values from the rows.
Of course, if you only need a few columns, it can also be a lot less data not to select all the columns you don’t need. Getting that data off the disk and sending it to whatever asked for it is significant overhead. Don’t do it unless you need to.
Other InnoDB index design considerations
Since InnoDB secondary indexes already contain all columns from the primary key, there’s no need to add them to the secondary index unless the index needs them at the front of the index. In particular, adding an index on
(price, variety) to the apples table above is completely redundant. And in tables where the primary key is several columns and it’s desirable to have the table “clustered two ways” by using the indexes as I’ve explained, not all of the columns need to be added to additional indexes. Indexes need to be designed very carefully to avoid causing a bunch of extra overhead. Every index adds a cost to the table, and it’s really important to avoid indexes that add cost but no benefit.
Suppose you added an index on
(price, variety) to the apples table anyway. You might think the variety column can just be optimized out of the internal nodes, since the values are already at the leaf nodes. It can’t, because the primary key values are only at the leaf nodes, not in the internal nodes, and they can’t be optimized out of the internal nodes because they’re needed for navigating the index. Again, adding that column to the end of the index will just make the index larger, but result in the query knowing nothing it didn’t already know—and that’s useless.
I want to point out that it’s not always possible to design indexes so this optimization can be used! It is not necessarily a good design goal to make sure every query can be satisfied without leaving the indexes. In fact, it’s unrealistic. But in special cases, it may be possible and worth doing.
Another InnoDB optimization
Here’s another neat optimization: a tiny index might be used unexpectedly. For example,
create table something (
id bigint not null auto_increment primary key,
is_something tinyint not null,
othercol_1 bigint not null,
othercol_2 bigint not null,
othercol_3 bigint not null,
index(is_something)
);
is_something is a 1⁄0 indicator of whether something is true about the row. Normally I’d say an index on that is a waste of disk and CPU, because it’s not selective enough for the query optimizer to use it, assuming there’s an equal distribution of ones and zeroes. But the fact that it’s a very small value is important for some queries. For example, select sum(id) from something will scan the is_something index because it’s the smallest available. Its internal nodes only have one-byte tinyint values, and the leaf nodes have a tinyint and an 8-byte bigint. That’s much smaller than the clustered index, which has 8-byte values in the internal nodes, and 33 bytes at each leaf.Proof of InnoDB’s automatic clustered index
I said every InnoDB table gets a 6-byte internal clustered index if it has no primary key. Here’s a neat way to see that in action. I created a table like so:
create table test(a int, b int, c int) engine=InnoDB;
insert into test values(1, 1, 1), (2, 2, 2);
I started a transaction and got an exclusive lock on it, then started another transaction on a different connection and tried to update that table:
– connection 1: set transaction isolation level serializable; start transaction; select * from test;
– connection 2: set transaction isolation level serializable; start transaction; update test set a = 5;
The query blocked and waited for a lock to be granted. Then I issued `SHOW ENGINE INNODB STATUS` on another connection. The transaction information shows the lock on the internally generated index:
—TRANSACTION 0 81411, ACTIVE 1410 sec, process no 8799, OS thread id 1141414240 starting index read mysql tables in use 1, locked 1 LOCK WAIT 2 lock struct(s), heap size 1216 MySQL thread id 4, query id 194 localhost xaprb Updating update test set a = 5 ——- TRX HAS BEEN WAITING 9 SEC FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 0 page no 131074 n bits 72 index
GEN_CLUST_INDEX of table test/test trx id 0 81411 lock_mode X waiting Record lock, heap no 2 PHYSICAL RECORD: n_fields 6; compact format; info bits 0 0: len 6; hex 000000018a02; asc ;; 1: len 6; hex 000000013e0a; asc > ;; 2: len 7; hex 80000000320110; asc 2 ;; 3: len 4; hex 80000001; asc ;; 4: len 4; hex 80000001; asc ;; 5: len 4; hex 80000001; asc ;;
Notice the lock on the index called `GEN_CLUST_INDEX`. Notice also the number of fields (`n_fields`) in the lock struct: two more than the number of columns in the table. The first field in the index is the internally generated unique value, and it is 6 bytes as I said above.
If there is a primary key on `a`, it's a different story:
—TRANSACTION 0 81456, ACTIVE 17 sec, process no 8799, OS thread id 1141680480 starting index read mysql tables in use 1, locked 1 LOCK WAIT 4 lock struct(s), heap size 1216 MySQL thread id 9, query id 277 localhost xaprb Updating update test set a = 5 where a = 1 ——- TRX HAS BEEN WAITING 6 SEC FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 0 page no 131076 n bits 72 index
PRIMARY of table test/test trx id 0 81456 lock_mode X locks rec but not gap waiting Record lock, heap no 2 PHYSICAL RECORD: n_fields 5; compact format; info bits 0 0: len 4; hex 80000001; asc ;; 1: len 6; hex 000000013e27; asc >‘;; 2: len 7; hex 80000000320110; asc 2 ;; 3: len 4; hex 80000001; asc ;; 4: len 4; hex 80000001; asc ;; ```
Now the lock is on the index called
PRIMARY, there are only 5 fields in the lock structure, and the first one is 4 bytes instead of 6. Fields with the value 2 have the hex value 80000001. When the primary key is a column, that field comes first in the lock structure.
These examples prove that InnoDB adds a “hidden column” to your tables when you don’t create a primary key. Maybe I’m saying this too often, but you should always create a carefully designed primary key, because if you don’t, you’re throwing away one of the best things InnoDB gives you: a clustered index. Read my past articles for more on how to design an effective primary key.








0 comments:
Post a Comment