One of the most common reasons for performance issues in software applications is missing or incorrect database indexes, so the goal of this article is to provide an introduction to the concepts and real-world practice of indexing for developers.
I'll be covering MySQL in this article, but the indexing concepts apply to any relational database engine.
Database Performance
There are many factors that impact database performance. The most obvious is the size of the data: as a database grows in size, queries begin to take longer to execute. A SELECT query that returned results quickly a few months ago could now be a bottleneck.
While there are different approaches to address performance problems like purging old data or de-normalization, the most effective solution is to properly index the database.
What's a database index?
An index is a data structure that speeds up data retrieval by sorting a number of records on one or more fields. It is akin to an index in a book which allows us to locate information quickly. In a database, indexes are a way to avoid scanning the full table to obtain the result that we're looking for.
The index entries act like pointers to the table rows, allowing the query to quickly determine which rows match a condition in the WHERE clause, and retrieve the other column values for those rows. All MySQL data types support indexing.
Index Types
MySQL supports different types of indexes based on the storage engine we're using.
B-Tree Index
The B-Tree index is the default index type for the InnoDB and MyISAM storage engines in MySQL. This is the most common index type used in databases so we’ll cover it in some detail.
B-Tree indexes can be used for a wide variety of queries. They work well for the following query patterns:
/* Full value */
SELECT id FROM users WHERE id = 100;/* Range Comparison */
SELECT id FROM users WHERE id > 100;/* Leftmost Prefix */
SELECT fname FROM users WHERE fname LIKE 'Alex%';
Let's take a look at the data structure of a B-Tree index. In the diagram, we have a root node and four leaf nodes.

B-Tree Design: Root Node + 4 Leaf Nodes
Each entry in a leaf node has a pointer to a row related to this index entry. All leaf nodes are linked together in a linked-list, left to right. Range lookups are very efficient since the values at the leaf nodes are sorted.
Index lookup is also pretty efficient. Let’s say we want to find data for entry 45. Instead of scanning the whole table, we can use an index. A quick check in the root node and it’s clear we need to go to fourth leaf node which covers entries 23 <= x < 100. So, we go to the second leaf node and find the entry for 9.
In the example, there are some empty spaces in the nodes. If we wanted to insert a row with an indexed value of 20, it can be inserted into the empty space in the third leaf node.

B-Tree Design: After insert of 20
What if we wanted to insert a row with indexed value of 50? We don't have enough room in the fourth leaf node to accommodate this so it has to be split. This is more computationally expensive than adding an entry to a leaf node.
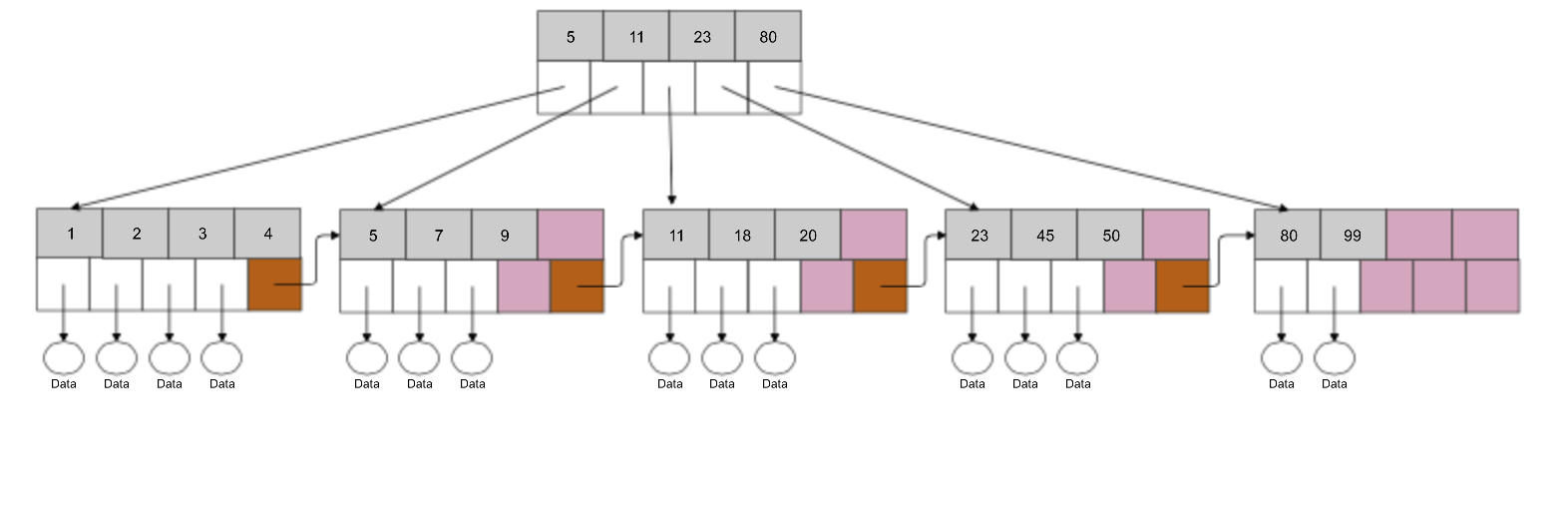
B-Tree Design: After insert of 50
Full Text Index
This type can be used for text lookups such a keyword searching. These indexes have always been available in MyISAM and were introduced in InnoDB starting in MySQL 5.6.
They cannot be used in conjunction with WHERE conditions. Instead, you would use the MATCH AGAINST operator.
Hash Index
Finally, we have hash indexes used in MEMORY and NDB engine. They are designed to handle equality comparisons and do not support range searches.
Employee Database Example
Let's download and import a sample employee database from GitHub.
This database contains 300,000 employee records and 2.8 million salary records so it is conducive to demonstrating the advantages of indexing.
git clone https://github.com/datacharmer/test_db.git
Cloning into 'test_db'...
remote: Counting objects: 94, done.
remote: Total 94 (delta 0), reused 0 (delta 0), pack-reused 94
Unpacking objects: 100% (94/94), done.
Checking connectivity... done.
cd test_db
mysql < employees.sql
INFO
CREATING DATABASE STRUCTURE
INFO
storage engine: InnoDB
INFO
LOADING departments
INFO
LOADING employees
INFO
LOADING dept_emp
INFO
LOADING dept_manager
INFO
LOADING titles
INFO
LOADING salaries
data_load_time_diff
00:00:57
Let's list the tables in the database:
mysql> use employees;
Database changed
mysql> show tables;
+----------------------+
| Tables_in_employees |
+----------------------+
| current_dept_emp |
| departments |
| dept_emp |
| dept_emp_latest_date |
| dept_manager |
| employees |
| salaries |
| titles |
+----------------------+
8 rows in set (0.00 sec)
The salaries table is the one we are most interested in here:
mysql> SELECT COUNT(emp_no) FROM salaries \G
*************************** 1. row ***************************
COUNT(emp_no): 2844047
1 row in set (0.56 sec)Showing the Indexes for a Table
The first thing to know here is that a table's primary key is always indexed.
Below we see that the salaries table has a composite primary key of (emp_no, from_date):
mysql> DESCRIBE salaries;
+-----------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------+------+-----+---------+-------+
| emp_no | int(11) | NO | PRI | NULL | |
| salary | int(11) | NO | | NULL | |
| from_date | date | NO | PRI | NULL | |
| to_date | date | NO | | NULL | |
+-----------+---------+------+-----+---------+-------+
4 rows in set (0.00 sec)
Next, we can display the index information using SHOW INDEX:
mysql> SHOW INDEX FROM salaries \G
*************************** 1. row ***************************
Table: salaries
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: emp_no
Collation: A
Cardinality: 275990
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: salaries
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 2
Column_name: from_date
Collation: A
Cardinality: 2557292
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
2 rows in set (0.00 sec)
As expected, the indexes correspond to the primary keys.
How do I know if my query is using an index?
The EXPLAIN keyword is an analytical tool that will show us which indexes are being utilized, how the table is being scanned and sorted, and other useful information. The key field will tell us if any indexes are used, and the rows field will tell us how many rows were examined to get the result.
Equality query using salary column in WHERE clause:
mysql> EXPLAIN SELECT emp_no FROM salaries WHERE salary = 50000 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: salaries
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2839089
filtered: 10.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
Range query using salary column in WHERE clause:
mysql> EXPLAIN SELECT emp_no FROM salaries WHERE salary > 100000 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: salaries
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2839089
filtered: 33.33
Extra: Using where
1 row in set, 1 warning (0.00 sec)
The above output shows key: NULL for both queries because salary column is not indexed. The value of the rows field (2839089) tell us that MySQL is doing a full table scan.
You may be wondering why that number isn't equal to the value returned by COUNT earlier (2844047). This reason is that table statistics used by EXPLAIN are based on system-cached values and are not guaranteed to be accurate.
Creating an Index
Let's assume our application is going to be making a lot of equality and range queries on employee salaries.
We can optimize these types of queries by creating an index on the salary column:
mysql> ALTER TABLE salaries ADD INDEX salary (salary);
Query OK, 0 rows affected (6.47 sec)
Records: 0 Duplicates: 0 Warnings: 0
Now, let's run our equality comparison query again:
mysql> EXPLAIN SELECT emp_no FROM salaries WHERE salary = 50000 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: salaries
partitions: NULL
type: ref
possible_keys: salary
key: salary
key_len: 4
ref: const
rows: 69
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
Notice the dramatic improvement here. The rows examined has dropped to 69 which is the number of results matching our condition.
The range comparison also shows a significant improvement to 191,348 (a reduction of 94%):
mysql> EXPLAIN SELECT emp_no FROM salaries WHERE salary > 100000 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: salaries
partitions: NULL
type: range
possible_keys: salary
key: salary
key_len: 4
ref: NULL
rows: 191348
filtered: 100.00
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
Indexing Pitfalls to Avoid
It's important to know that creating indexes introduces a performance penalty for write operations (INSERT, UPDATE, and DELETE). Each time the rows in a table are modified, any related indexes are updated automatically. For this reason, it's important to avoid create indexes on columns that don't provide any value.
Finding the right balance is key to achieving fast queries using an optimal set of indexes.








0 comments:
Post a Comment